機器人的å„類具身æ“作任務(wù)天然就å°èªžè¨€æŒ‡ä»¤ç†è§£ã€å ´æ™¯æ„ŸçŸ¥å’Œæ™‚空è¦(guÄ«)劃ç‰èƒ½åŠ›æœ‰è‘—很高的è¦æ±‚,這自然引申出一個å•é¡Œï¼šèƒ½ä¸èƒ½å……分利用大模型能力,將其é·ç§»åˆ°æ©Ÿå™¨äººé ˜(lÇng)域,直接è¦(guÄ«)劃底層動作åºåˆ—呢?
å°æ¤ï¼ŒByteDance Research 基于開æºçš„多模態(tà i)語言視覺大模型 OpenFlamingo 開發(fÄ)了開æºã€æ˜“用的 RoboFlamingo 機器人æ“作模型,åªç”¨å–®æ©Ÿå°±å¯ä»¥è¨“(xùn)練。使用簡單ã€å°‘é‡çš„微調(dià o)å°±å¯ä»¥æŠŠ VLM è®Šæˆ Robotics VLM,從而é©ç”¨äºŽèªžè¨€äº¤äº’的機器人æ“作任務(wù)。 OpenFlamingo 在機器人æ“作數(shù)æ“š(jù)集 CALVIN 上進行了驗è‰ï¼Œå¯¦é©—çµ(jié)果表明,RoboFlamingo åªåˆ©ç”¨äº† 1% 的帶語言標(biÄo)注的數(shù)æ“š(jù)å³åœ¨ä¸€ç³»åˆ—機器人æ“作任務(wù)上å–得了 SOTA 的性能。隨著 RT-X 數(shù)æ“š(jù)集開放,采用開æºæ•¸(shù)æ“š(jù)é (yù)訓(xùn)ç·´ RoboFlamingo 并 finetune 到ä¸åŒæ©Ÿå™¨äººå¹³è‡ºï¼Œå°‡æœ‰å¸Œæœ›æˆç‚ºä¸€å€‹ç°¡å–®æœ‰æ•ˆçš„機器人大模型 pipeline。論文還測試了å„種ä¸åŒ policy headã€ä¸åŒè¨“(xùn)練范å¼å’Œä¸åŒ Flamingo çµ(jié)構(gòu)çš„ VLM 在 Robotics 任務(wù)上微調(dià o)的表ç¾(xià n),得到了一些有æ„æ€çš„çµ(jié)論。

ç ”ç©¶èƒŒæ™¯
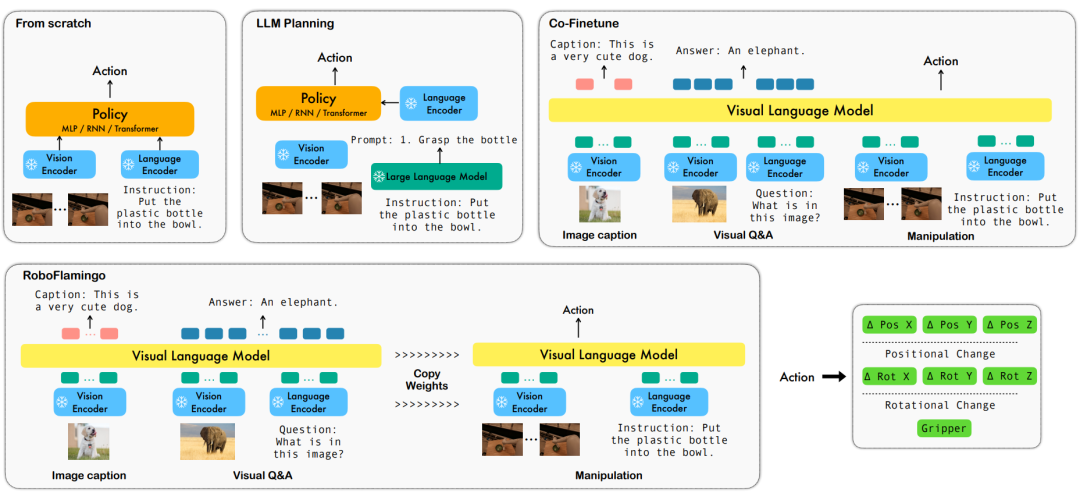
基于語言的機器人æ“ä½œæ˜¯å…·èº«æ™ºèƒ½é ˜(lÇng)域的一個é‡è¦æ‡‰(yÄ«ng)用,它涉åŠåˆ°å¤šæ¨¡æ…‹(tà i)數(shù)æ“š(jù)çš„ç†è§£å’Œè™•ç†ï¼ŒåŒ…括視覺ã€èªžè¨€å’ŒæŽ§åˆ¶ç‰ã€‚近年來,視覺語言基礎(chÇ”)模型(VLMs)已經(jÄ«ng)åœ¨å¤šå€‹é ˜(lÇng)域å–得了顯著的進展,包括圖åƒæè¿°ã€è¦–覺å•ç”和圖åƒç”Ÿæˆç‰ã€‚然而,將這些模型應(yÄ«ng)用于機器人æ“作ä»ç„¶å˜åœ¨ä¸€äº›æŒ‘戰(zhà n),例如如何將視覺和語言信æ¯çµ(jié)åˆèµ·ä¾†ï¼Œå¦‚何處ç†æ©Ÿå™¨äººæ“作的時åºæ€§ç‰ã€‚ 為了解決這些å•é¡Œï¼ŒByteDance Research çš„æ©Ÿå™¨äººç ”ç©¶åœ˜éšŠåˆ©ç”¨ç¾(xià n)æœ‰çš„é–‹æº VLM,OpenFlamingo,è¨(shè)計了一套新的視覺語言æ“作框架,RoboFlamingoã€‚å…¶ä¸ VLM å¯ä»¥é€²è¡Œå–®æ¥è¦–覺語言ç†è§£ï¼Œè€Œé¡å¤–çš„ policy head 模組被用來處ç†æ·å²ä¿¡æ¯ã€‚åªéœ€è¦ç°¡å–®çš„微調(dià o)方法就能讓 RoboFlamingo é©æ‡‰(yÄ«ng)于基于語言的機器人æ“作任務(wù)。 RoboFlamingo 在基于語言的機器人æ“作數(shù)æ“š(jù)集 CALVIN 上進行了驗è‰ï¼Œå¯¦é©—çµ(jié)果表明,RoboFlamingo åªåˆ©ç”¨äº† 1% 的帶語言標(biÄo)注的數(shù)æ“š(jù)å³åœ¨ä¸€ç³»åˆ—機器人æ“作任務(wù)上å–得了 SOTA 的性能(多任務(wù)å¸(xué)ç¿’(xÃ)çš„ task sequence æˆåŠŸçŽ‡ç‚º 66%,平å‡ä»»å‹™(wù)完æˆæ•¸(shù)é‡ç‚º 4.09,基線方法為 38%,平å‡ä»»å‹™(wù)完æˆæ•¸(shù)é‡ç‚º 3.06ï¼›zero-shot 任務(wù)çš„æˆåŠŸçŽ‡ç‚º 24%,平å‡ä»»å‹™(wù)完æˆæ•¸(shù)é‡ç‚º 2.48,基線方法為 1%,平å‡ä»»å‹™(wù)完æˆæ•¸(shù)é‡æ˜¯ 0.67ï¼‰ï¼Œå¹¶ä¸”èƒ½å¤ é€šéŽé–‹ç’°(huán)控制實ç¾(xià n)實時響應(yÄ«ng),å¯ä»¥éˆæ´»éƒ¨ç½²åœ¨è¼ƒä½Žæ€§èƒ½çš„平臺上。這些çµ(jié)果表明,RoboFlamingo 是一種有效的機器人æ“作方法,å¯ä»¥ç‚ºæœªä¾†çš„機器人應(yÄ«ng)用æ供有用的åƒè€ƒã€‚ 方法
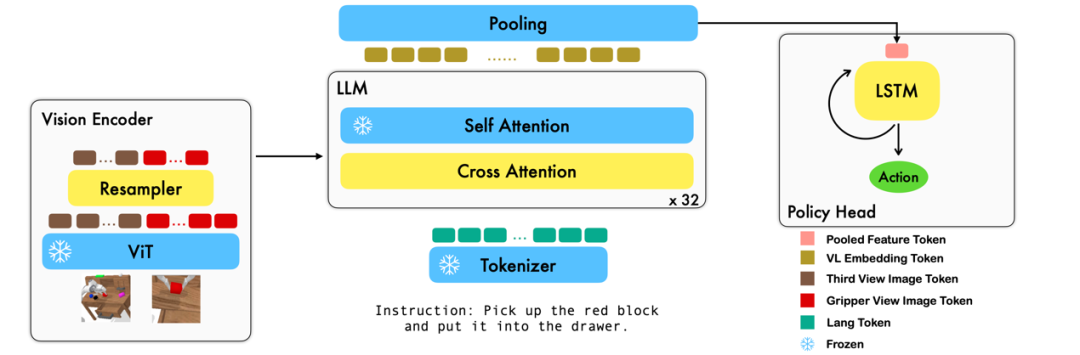
æœ¬å·¥ä½œåˆ©ç”¨å·²æœ‰çš„åŸºäºŽåœ–åƒ - 文本å°çš„視覺語言基礎(chÇ”)模型,通éŽè¨“(xùn)練端到端的方å¼ç”Ÿæˆæ©Ÿå™¨äººæ¯ä¸€æ¥çš„ relative action。模型的主è¦æ¨¡å¡ŠåŒ…å«äº† vision encoder,feature fusion decoder å’Œ policy head 三個模塊。Vision encoder 模塊先將當(dÄng)å‰è¦–覺觀測輸入到 ViT ä¸ï¼Œå¹¶é€šéŽ resampler å° ViT 輸出的 token 進行 down sample。Feature fusion decoder å°‡ text token 作為輸入,并在æ¯å€‹ layer ä¸å…ˆå°‡ vision encoder çš„ output 作為 query 進行 cross attention,之åŽé€²è¡Œ self attention 以完æˆè¦–覺與語言特å¾çš„èžåˆã€‚最åŽï¼Œå° feature fusion decoder 進行 max pooling åŽå°‡å…¶é€å…¥ policy head ä¸ï¼Œpolicy head æ ¹æ“š(jù) feature fusion decoder 輸出的當(dÄng)å‰å’Œæ·å² token åºåˆ—直接輸出當(dÄng)å‰çš„ 7 DoF relative action,包括了 6-dim 的機械臂末端ä½å§¿å’Œ 1-dim çš„ gripper open/close。 在訓(xùn)ç·´éŽç¨‹ä¸ï¼ŒRoboFlamingo 利用é (yù)訓(xùn)ç·´çš„ ViTã€LLM å’Œ Cross Attention åƒæ•¸(shù),并åªå¾®èª¿(dià o) resamplerã€cross attention å’Œ policy head çš„åƒæ•¸(shù)。 實驗çµ(jié)果數(shù)æ“š(jù)集:
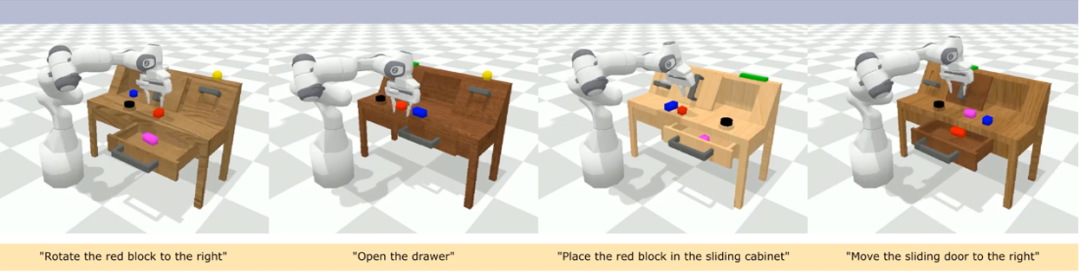
CALVIN(Composing Actions from Language and Vision)是一個開æºçš„模擬基準測試,用于å¸(xué)ç¿’(xÃ)基于語言的 long-horizon æ“作任務(wù)。與ç¾(xià n)有的視覺 - 語言任務(wù)數(shù)æ“š(jù)集相比,CALVIN 的任務(wù)在åºåˆ—長度ã€å‹•ä½œç©ºé–“和語言上都更為復(fù)雜,并支æŒéˆæ´»åœ°æŒ‡å®šå‚³æ„Ÿå™¨è¼¸å…¥ã€‚CALVIN 分為 ABCD 四個 split,æ¯å€‹ split å°æ‡‰(yÄ«ng)了ä¸åŒçš„ context å’Œ layout。 定é‡åˆ†æžï¼š
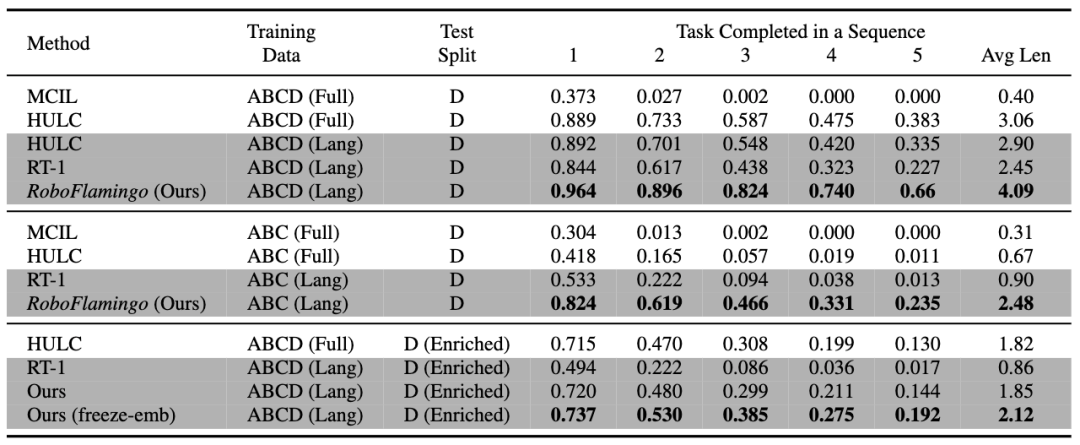
RoboFlamingo 在å„è¨(shè)置和指標(biÄo)上的性能å‡ç‚ºæœ€ä½³ï¼Œèªªæ˜Žäº†å…¶å…·æœ‰å¾ˆå¼·çš„模仿能力ã€è¦–覺泛化能力以åŠèªžè¨€æ³›åŒ–能力。Full å’Œ Lang 表示模型是å¦ä½¿ç”¨æœªé…å°çš„視覺數(shù)æ“š(jù)進行訓(xùn)練(å³æ²’有語言é…å°çš„視覺數(shù)æ“š(jù));Freeze-emb 指的是å‡çµ(jié)èžåˆè§£ç¢¼å™¨çš„嵌入層;Enriched 表示使用 GPT-4 增強的指令。 消èžå¯¦é©—:
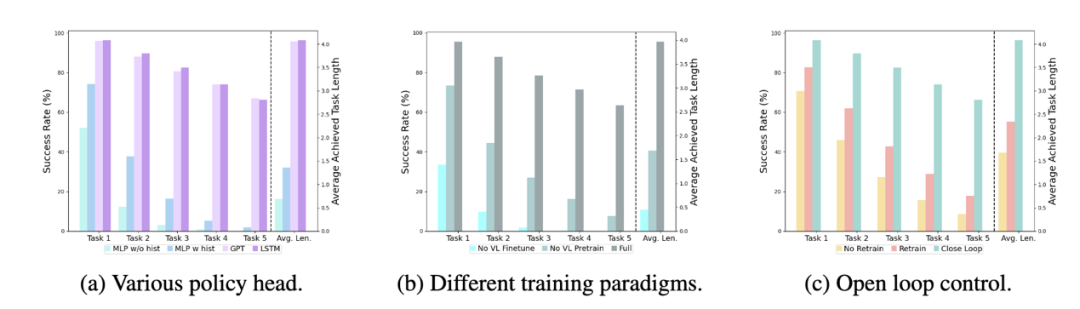
ä¸åŒçš„ policy head: 實驗考察了四種ä¸åŒçš„ç–ç•¥é 部:MLP w/o histã€MLP w histã€GPT å’Œ LSTM。其ä¸ï¼ŒMLP w/o hist ç›´æŽ¥æ ¹æ“š(jù)當(dÄng)å‰è§€æ¸¬é (yù)測æ·å²ï¼Œå…¶æ€§èƒ½æœ€å·®ï¼ŒMLP w hist å°‡æ·å²è§€æ¸¬åœ¨ vision encoder 端進行èžåˆåŽé (yù)測 action,性能有所æå‡ï¼›GPT å’Œ LSTM 在 policy head 處分別顯å¼ã€éš±å¼åœ°ç¶è·æ·å²ä¿¡æ¯ï¼Œå…¶è¡¨ç¾(xià n)æœ€å¥½ï¼Œèªªæ˜Žäº†é€šéŽ policy head 進行æ·å²ä¿¡æ¯èžåˆçš„有效性。 視覺-語言é (yù)訓(xùn)練的影響: é (yù)訓(xùn)ç·´å°äºŽ RoboFlamingo 的性能æå‡èµ·åˆ°äº†é—œ(guÄn)éµä½œç”¨ã€‚實驗顯示,通éŽé (yù)先在大型視覺-語言數(shù)æ“š(jù)集上進行訓(xùn)練,RoboFlamingo 在機器人任務(wù)ä¸è¡¨ç¾(xià n)得更好。 模型大å°èˆ‡æ€§èƒ½ï¼š 雖然通常更大的模型會帶來更好的性能,但實驗çµ(jié)果表明,å³ä½¿æ˜¯è¼ƒå°çš„模型,也能在æŸäº›ä»»å‹™(wù)上與大型模型媲美。 指令微調(dià o)的影響: 指令微調(dià o)是一個強大的技巧,實驗çµ(jié)果表明,它å¯ä»¥é€²ä¸€æ¥æ高模型的性能。
定性çµ(jié)果相較于基線方法,RoboFlamingo ä¸ä½†å®Œæ•´åŸ·(zhÃ)行了 5 個連續(xù)çš„å任務(wù),且å°äºŽåŸºç·šé 執(zhÃ)è¡ŒæˆåŠŸçš„å‰å…©å€‹å任務(wù),RoboFlamingo 所用的æ¥æ•¸(shù)也明顯更少。
總çµ(jié)本工作為語言交互的機器人æ“作ç–ç•¥æ供了一個新穎的基于ç¾(xià n)æœ‰é–‹æº VLMs 的框架,使用簡單微調(dià o)就能實ç¾(xià n)出色的效果。RoboFlamingo 為機器人技術(shù)ç ”ç©¶è€…æ供了一個強大的開æºæ¡†æž¶ï¼Œèƒ½å¤ 更容易地發(fÄ)æ®é–‹æº VLMs 的潛能。工作ä¸è±å¯Œçš„實驗çµ(jié)果或許å¯ä»¥ç‚ºæ©Ÿå™¨äººæŠ€è¡“(shù)的實際應(yÄ«ng)用æ供寶貴的經(jÄ«ng)驗和數(shù)æ“š(jù)ï¼Œæœ‰åŠ©äºŽæœªä¾†çš„ç ”ç©¶å’ŒæŠ€è¡“(shù)發(fÄ)展。


















 網(wÇŽng)站客æœ
網(wÇŽng)站客æœ 粵公網(wÇŽng)安備 44030402000946號
粵公網(wǎng)安備 44030402000946號