時間:2023-10-26 15:21:14來源:國產FPGA之家
1ChatGPT和后摩爾時代
2023年,人工智能領域發生了一件里程碑式的事件:OpenAI發布了基于大型語言模型的聊天機器人ChatGPT,這是一個可以響應人類指令的聊天機器人,可以完成從寫文章、做數學題到調試代碼的各種任務。ChatGPT的發布刷新了人們對AI的認知,標志著生成式人工智能的商業化啟動,它不僅改變了AI研究和技術開發的方式,還對社會產生了深遠影響。然而,人工智能并不是一項新興的技術,而是起源于20世紀60年代,經過半個多世紀的發展,經歷了符號主義、連接主義和行為主體三次浪潮的相互交織,現階段大家普遍認為,人工智能 = 深度學習 + 大規模計算 + 大數據。深度學習是一種特殊的機器學習,它需要以大量的數據為基礎,通過“訓練”得到各種參數(模型),然后使用訓練得到的模型進行推理,得到最終的結果。因此,模型的參數越多,訓練和推理所需要的算力就越大。隨著深度學習的發展,AI領域對算力的需求以每年超過10倍的速度增長,以ChatGPT為例,其初版基于的大模型GPT-3是一個有著1750億個參數的巨型模型,而最新版基于的GPT-4,其參數量竟然達到了喪心病狂的1.76萬億(網傳)。
人工智能的實現需要算力,而算力的的實現則需要芯片的支撐,這是人工智能進行發展并實現產業化的關鍵。仍以GPT-3為例,1750億參數,1000億詞匯語料庫,需要1000塊英偉達A100 GPU訓練一個月。2023年,在芯片領域同樣發生了一件大事,3月24日,摩爾定律的提出者,戈登·摩爾先生與世長辭,享年94歲。摩爾曾在1965年對集成電路的發展做出了著名的預測:集成電路上可以容納的晶體管數目大約每經18到24個月便會增加一倍,即處理器的性能大約每兩年翻一倍,同時價格降為原來的一半,這便是大名鼎鼎的摩爾定律。
雖然摩爾定律并不是正式定義的科學定律,而是摩爾對他所觀察到的趨勢的歸納總結,但是在提出后的半個世紀中,成功預測了集成電路的發展趨勢。以英特爾為例,從1971年到2008年,在過去的幾十年里,英特爾微處理器芯片上最大晶體管的數量每兩年翻一番,而且特征尺寸以每年15%的速度縮減,每5年縮減一半。受益于特征尺寸的縮減,即使保持硬件架構不變,時鐘頻率也能獲得大幅度的提升。仍以英特爾為例,從1990年到2002年,其微處理器的時鐘頻率不到兩年就翻一番,當然這其中也包含架構升級帶來的提升。
如果照這個趨勢發展下去,那么2008年時,處理器的時鐘頻率就會提升到30GHz,然而實際上,2002年后,英特爾處理器時鐘頻率的增長就逐步放緩,并且在2005年達到頂峰。2004年11月,英特爾宣布取消時鐘頻率4GHz奔騰處理器的計劃,轉而研究多核架構。是的,雖然半個多世紀以來,摩爾定律為集成電路的發展描繪了美好的藍圖,但是由于物理效應、功耗等多方面的限制,摩爾定律不可能一直延續下去。物理效應方面,隨著工藝節點不斷縮小,晶體管的尺寸已經接近原子尺度,一些量子效應和噪聲效應會影響晶體管的正常工作。例如,當閘極長度足夠短時,就會發生量子隧穿效應,導致漏電流增加,同時也會增加功耗和溫度。
另外,由于晶體管中原子的數量越來越少,雜質漲落、界面粗糙度、晶格不匹配等因素也會造成晶體管之間的性能差異。功耗方面,隨著集成度的提高,芯片上的晶體管數量和時鐘頻率也相應增加,這會導致芯片的功耗和散熱問題變得更加嚴重。功耗主要包括靜態功耗和動態功耗兩部分。
靜態功耗是指晶體管在關閉狀態下仍然存在的漏電流所消耗的功率,它與量子隧穿效應有關。動態功耗是指晶體管在開關狀態下由于電容充放電所消耗的功率,它與時鐘頻率和電壓有關。除此之外,經濟效益也是需要考慮的一個方面,隨著工藝節點的進步,制造芯片所需的設備、材料和人力成本也不斷增加,這會影響芯片的價格和市場競爭力。
早在摩爾先生去世之前十幾年,業界就認識到摩爾定律的發展逐漸放緩甚至將要被打破,于是提出后摩爾時代這個概念,力求以后的集成電路發展尋找新的技術路線。目前,業界提出了延續摩爾(More Moore)、擴展摩爾(More than Moore)、超越摩爾(Beyond Moore)和豐富摩爾(Much Moore)等四種主要的發展方向。由于芯片的時鐘頻率不能繼續提升,因此處理器的設計從單核超頻逐漸向多核并行轉變,通過提供多個相同的核心,將計算任務分解到不同的核心上同時計算,從而提高處理性能。然而,隨著處理器面臨的場景和處理的任務越來越復雜,不同的任務可能具有不同的性能和能效限制。
沒有任何處理器架構適合所有的場景,因此,多核處理器的設計從多核同構逐漸向多核異構轉變,即處理器中的核心具有不同的架構,比如一些是高性能的、一些是低功耗的,或者一些是通用的、一些是專用的。
2后摩爾時代下的AI芯片
如前所述,以ChatGPT為代表的AI應用需要極大的算力作為支撐,而算力作為人工智能的三大要素之一,需要AI芯片的支撐。雖然,從廣義上來說,所有面向AI應用的芯片都可以稱為AI芯片,但是人們普遍認為,AI芯片是針對AI算法做了特殊加速設計的芯片。由于深度學習需要很高的并行計算能力,而CPU的架構往往無法充分滿足人工智能高性能并行計算需求,因此需要發展適合AI算法的專屬芯片。
目前常見的AI加速芯片按照技術路線可以分為GPU、FPGA和ASIC三類:1)GPU:由數以千計的更小、更高效的核心組成大規模并行計算架構,適合用于大量并行計算。2)FPGA:一種半定制芯片,靈活性強集成度高,但運算量小且量產成本高,適用于算法更新頻繁的專用領域3)ASIC:領域專用芯片,專用性非常強,開發周期較長且難度極高,適合市場需求量大的專用領域。下表更詳細的對比了三者的優缺點:
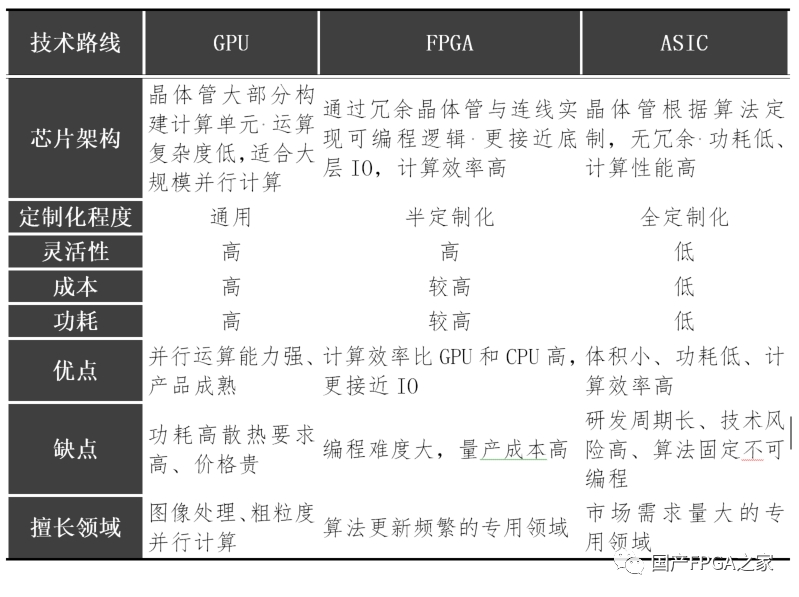
雖然說CPU不能滿足AI算法的性能要求,因此不能作為AI專用芯片,但是實際上真正的AI應用場景都需要CPU的參與才能完成。這是因為CPU具有其他AI專用芯片所不具備的通用處理能力,而在AI應用中,數據的前處理、計算過程的流程控制以及計算結果的后處理等等,都需要CPU的通用處理能力才能完成。如前所述,在后摩爾時代,處理器的設計多以多核異構為主,各個處理單元充分發揮自己所長,大家相互配合從而高效地完成計算。而AI處理器作為后摩爾時代芯片設計中的代表,自然也需要采用這種異構多核的設計方式。當然,不同的AI處理器面向的場景不同,具體的異構設計也不相同。
以邊緣端的AI處理器為例,其面向的場景需要低功耗、高性能以及數據處理的實時性,因此可以采用傳統的SoC設計外加專用的AI處理器(ASIC),其中SoC中的CPU和外設分別提供了通用處理和IO交互等能力,而專用AI處理器則為AI算法進行加速,二者結合兼顧了在AI計算場景中的高性能和低功耗。然而,美中不足的是,AI專用處理器雖然性能高,但是靈活性不足,其所支持的算法在設計完成時便已確定,后期無法靈活的添加;而AI算法的發展日新月異,新算子層出不窮,只靠AI處理器恐怕難以招架。
如果能夠在這套系統中再添加一片FPGA,那么靈活性則會極大的提高。如果遇到不支持的算法或者不能滿足的(IO)性能需求,只需要通過FPGA的可編程邏輯進行現場定制開發,就能輕易的支持。3FPAI = FPGA + SOC + AI如上所述,對于邊緣端的AI處理器,采用FPFA、SoC和專用AI處理器相結合的設計,便能兼顧通用性、靈活性和能效,我們不妨將以上架構命名為FPAI,即 FPAI = FPGA + SoC + AI。以上架構雖然好,但是由于涉及到FPGA的集成,因此實際設計和生產的難度都比較大。萬幸的是,某國內廠商敢為人先,已經率先推出了采用FPAI架構的AI處理器。該芯片的架構如下圖所示:
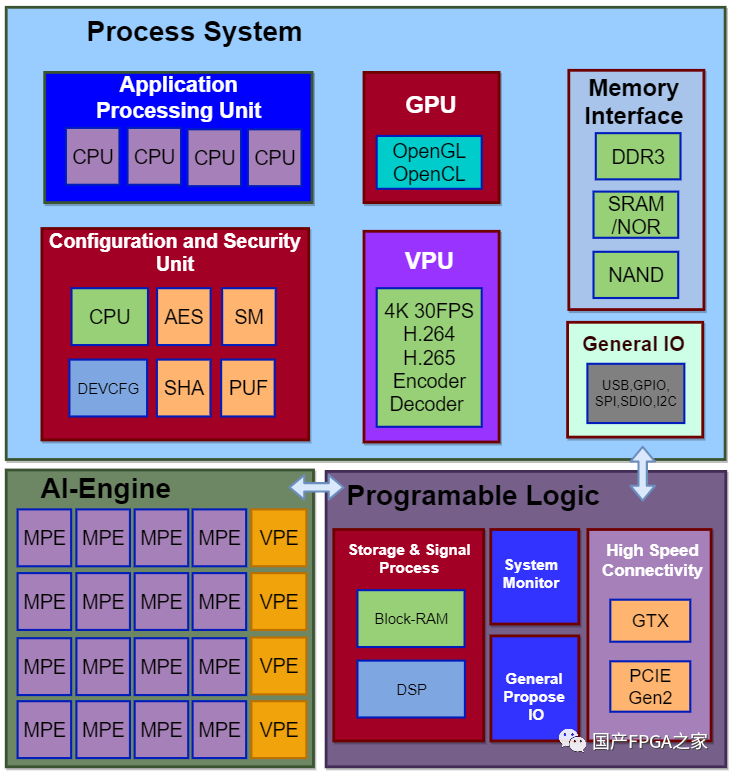
該芯片主要包含了以下三部分:
1)處理器系統:對應FPAI架構中的SoC,主要包含多核CPU/GPU/VPU等處理器、總線、存儲單元、一些通用接口和其他功能
2)AI引擎:對應FPAI架構中的AI專用處理器,包含矩陣處理引擎(MPE)、向量處理引擎(VPE)、片上存儲和一些其他計算引擎。其中MPE主要用于乘累加的計算,其主要計算單元是一個32×32的MAC陣列;VPE主要用于向量的線性計算以及激活和池化等操作;片上存儲用于緩存中間數據,緩解帶寬壓力。3)可編程邏輯:對應FPAI架構中的FPGA,包含可編程邏輯資源(BRAM, LUT, DSP),高速接口(GTH, ETH, PCIE)和DDR等。
該AI處理器支持INT8和INT16兩種計算精度,分別提供27.5TOPS和6.9TOPS的算力。運行Yolov5s網絡,耗時6.28ms,浮點精度為0.568,量化后的INT8精度為0.547,INT16精度為0.561。
處理器的多核異構設計會給編程帶來很大的復雜度,因此一款好的AI處理器不僅要有好的性能和能效,還要提供好用的編譯器來將上層AI應用便捷地部署到AI處理器上加速運行。上述FPAI架構的處理器就提供了功能強大且靈活的AI編譯器“Icraft”,其整體架構如下:
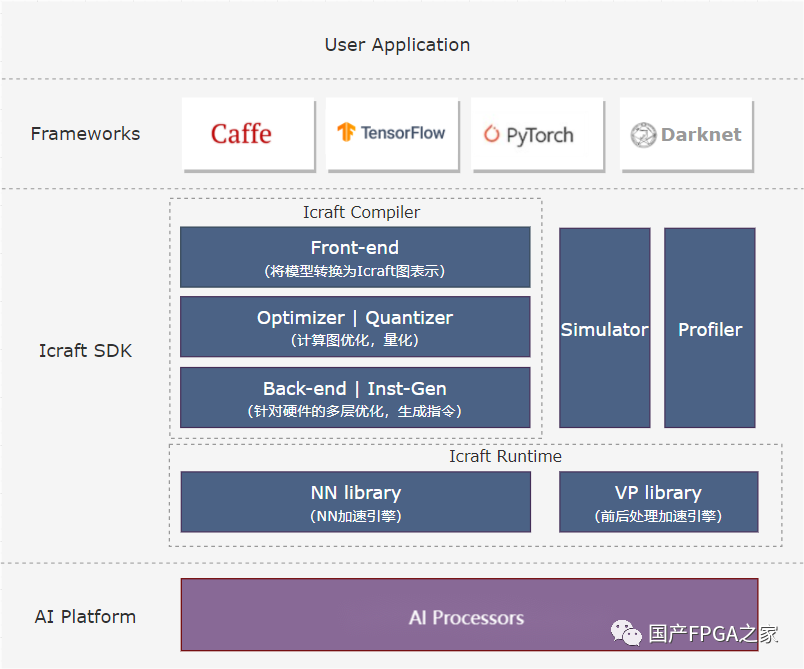
Icraft主要有以下組件:
1)前端解析:將AI框架中的模型解析到Icraft的中間層,支持的前端框架:Pytorch、Tensorflow、ONNX、Caffe、Darknet
2)量化&優化:對框架中解析出來的中間層網絡進行量化和一系列優化,一步步適配到AI處理器3)指令生成:將算子轉換成AI引擎的指令序列4)仿真&運行:對中間層網絡進行仿真,或者將編譯好的網絡部署到AI處理器上運行5)分析評估:對網絡的運行速度、效率等情況進行分析評估,為性能優化提供參考。Icraft對于FPAI架構中的FPGA部分提供了強有力的支持,用戶可以在FPGA編程定制自己所需要的加速邏輯,并通過Icraft的自定義算子接口加入到編譯流程中,這樣用戶可以選擇將任何算子通過FPGA編程進行加速,從而靈活的滿足不同場景的需求。由于篇幅限制,具體的自定義算子流程后面將專門撰文講述。
戰術總結
今天主要給大家講述了在后摩爾時代,處理器異構多核設計的重要性。同時,針對邊緣端AI處理器的設計介紹了FPAI (FPGA + SOC + AI) 架構的優勢,并且具體介紹了一款已經上市的FPAI架構的加速器的硬件和軟件設計。各位老鐵,如果對這款FPAI芯片感興趣的話,歡迎私信一起交流,小編我會第一時間邀請技術大拿答疑解惑!
上一篇:“摻硅補鋰”電池技術,如何...
下一篇:動力電池制造過程的卷繞工藝...
中國傳動網版權與免責聲明:凡本網注明[來源:中國傳動網]的所有文字、圖片、音視和視頻文件,版權均為中國傳動網(www.siyutn.com)獨家所有。如需轉載請與0755-82949061聯系。任何媒體、網站或個人轉載使用時須注明來源“中國傳動網”,違反者本網將追究其法律責任。
本網轉載并注明其他來源的稿件,均來自互聯網或業內投稿人士,版權屬于原版權人。轉載請保留稿件來源及作者,禁止擅自篡改,違者自負版權法律責任。
產品新聞
更多>
2025-06-06

2025-05-19

2025-04-30

2025-04-11

2025-04-08

2025-03-31












 網站客服
網站客服 粵公網安備 44030402000946號
粵公網安備 44030402000946號